

Since the introduction of generative AI, large language models (LLMs) have conquered the world and found their way into search engines.
But is it possible to proactively influence AI performance via large language model optimization (LLMO) or generative AI optimization (GAIO)?
This article discusses the evolving landscape of SEO and the uncertain future of LLM optimization in AI-powered search engines, with insights from data science experts.
What is LLM optimization or generative AI optimization (GAIO)?
GAIO aims to help companies position their brands and products in the outputs of leading LLMs, such as GPT and Google Bard, prominent as these models can influence many future purchase decisions.
For example, if you search Bing Chat for the best running shoes for a 96-kilogram runner who runs 20 kilometers per week, Brooks, Saucony, Hoka and New Balance shoes will be suggested.
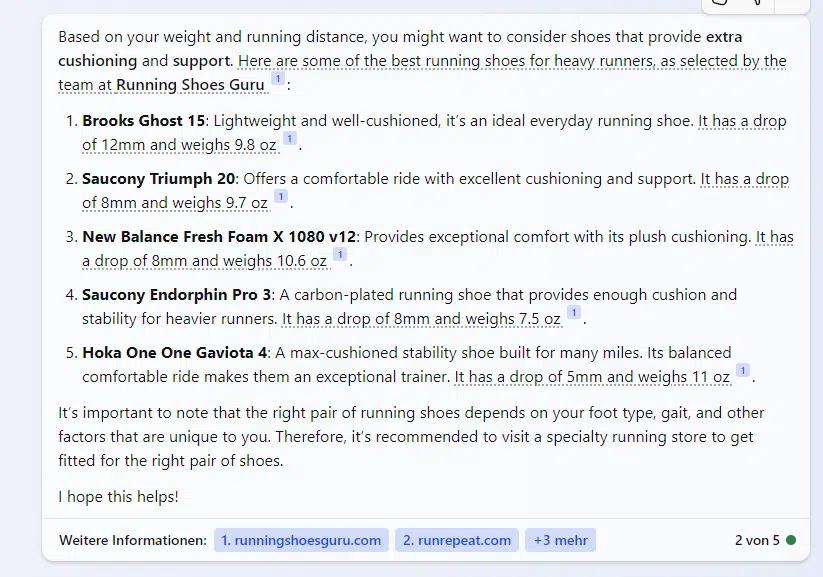
When you ask Bing Chat for safe, family-friendly cars that are big enough for shopping and travel, it suggests Kia, Toyota, Hyundai and Chevrolet models.
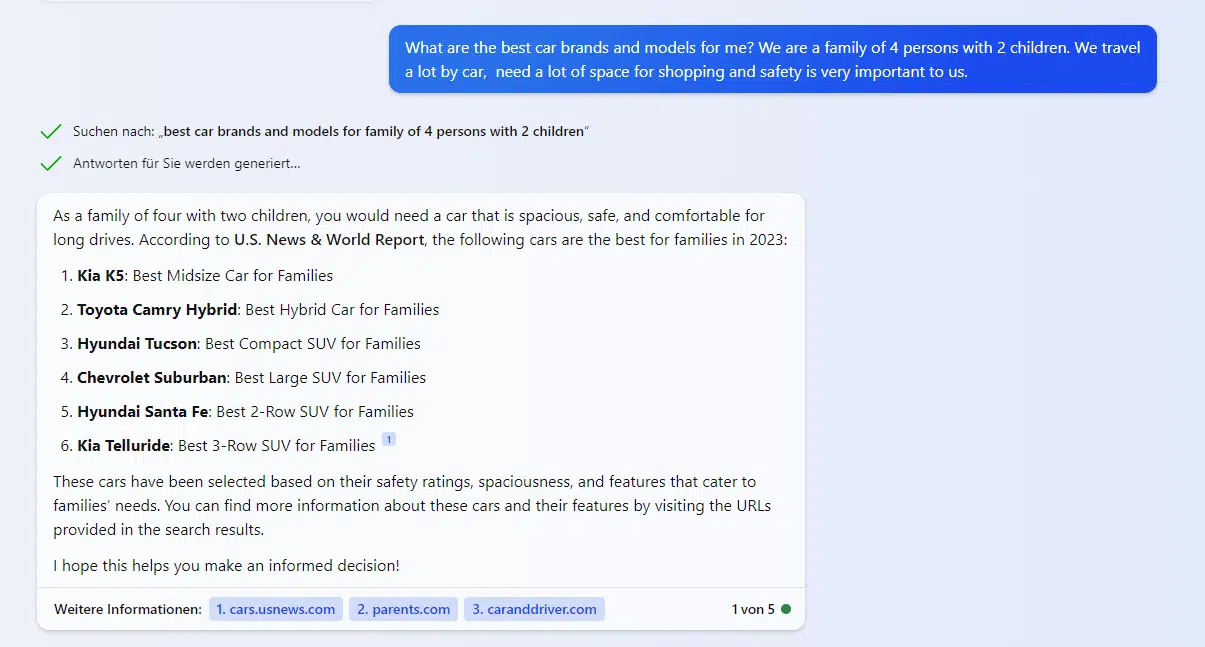
The approach of potential methods such as LLM optimization is to give preference to certain brands and products when dealing with corresponding transaction-oriented questions.
How are these recommendations made?
Suggestions from Bing Chat and other generative AI tools are always contextual. The AI mostly uses neutral secondary sources such as trade magazines, news sites, association and public institution websites, and blogs as a source for recommendations.
The output of generative AI is based on the determination of statistical frequencies. The more often words appear in sequence in the source data, the more likely it is that the desired word is the correct one in the output.
Words frequently mentioned in the training data are statistically more similar or semantically more closely related.
Which brands and products are mentioned in a certain context can be explained by the way LLMs work.
LLMs in action
Modern transformer-based LLMs such as GPT or Bard are based on a statistical analysis of the co-occurrence of tokens or words.
To do this, texts and data are broken down into tokens for machine processing and positioned in semantic spaces using vectors. Vectors can also be whole words (Word2Vec), entities (Node2Vec), and attributes.
In semantics, the semantic space is also described as an ontology. Since LLMs rely more on statistics than semantics, they are not ontologies. However, the AI gets closer to semantic understanding due to the amount of data.
Semantic proximity can be determined by Euclidean distance or cosine angle measure in semantic space.

If an entity is frequently mentioned in connection with certain other entities or properties in the training data, there is a high statistical probability of a semantic relationship.
The method of this processing is called transformer-based natural language processing.
NLP describes a process of transforming natural language into a machine-understandable form that enables communication between humans and machines.
NLP comprises natural language understanding (NLU) and natural language generation (NLG).
When training LLMs, the focus is on NLU, and when outputting AI-generated results,








